Schema is a logical description of the entire database. It includes the name and description of records of all record types including all associated data-items and aggregates. Much like a database, a data warehouse also requires to maintain a schema. A database uses relational model, while a data warehouse uses Star, Snowflake, and Fact Constellation schema. In this chapter, we will discuss the schemas used in a data warehouse.
Star Schema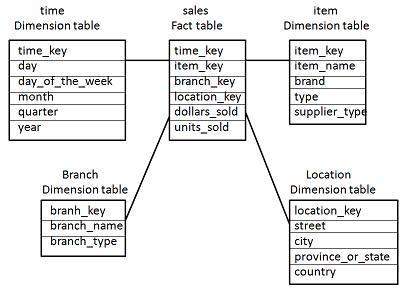 Snowflake Schema
Snowflake Schema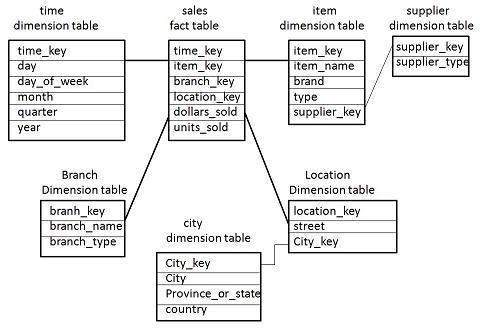
Each dimension in a star schema is represented with only one-dimension table.
This dimension table contains the set of attributes.
The following diagram shows the sales data of a company with respect to the four dimensions, namely time, item, branch, and location.
There is a fact table at the center. It contains the keys to each of four dimensions.
The fact table also contains the attributes, namely dollars sold and units sold.
Note − Each dimension has only one dimension table and each table holds a set of attributes. For example, the location dimension table contains the attribute set {location_key, street, city, province_or_state,country}. This constraint may cause data redundancy. For example, "Vancouver" and "Victoria" both the cities are in the Canadian province of British Columbia. The entries for such cities may cause data redundancy along the attributes province_or_state and country.
Some dimension tables in the Snowflake schema are normalized.
The normalization splits up the data into additional tables.
Unlike Star schema, the dimensions table in a snowflake schema are normalized. For example, the item dimension table in star schema is normalized and split into two dimension tables, namely item and supplier table.
Now the item dimension table contains the attributes item_key, item_name, type, brand, and supplier-key.
The supplier key is linked to the supplier dimension table. The supplier dimension table contains the attributes supplier_key and supplier_type.
Note − Due to normalization in the Snowflake schema, the redundancy is reduced and therefore, it becomes easy to maintain and the save storage space.
No comments:
Post a Comment